

Authors:
(1) Shengqiong Wu, NExT++, School of Computing, National University of Singapore;
(2) Hao Fei ,from NExT++, School of Computing at the National University of Singapore, serves as the corresponding author: [email protected].
(3) Leigang Qu, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: [email protected];;
(4) Wei Ji, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: [email protected];;
(5) Tat-Seng Chua, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: [email protected];.
Table of Links
- Abstract and 1. Introduction
- 2 Related Work
3 Overall Architecture
4 Lightweight Multimodal Alignment Learning - 5 Modality-switching Instruction Tuning
- 5.1 Instruction Tuning
- 5.2 Instruction Dataset
- 6 Experiments
- 6.1 Any-to-any Multimodal Generation and 6.2 Example Demonstrations
- 7 Conclusion and References
5.2 Instruction Dataset
For the IT of NExT-GPT, we consider the following datasets.
‘Text+X’ — ‘Text’ Data The commonly used datasets for MM-LLM IT entail inputs of both texts and multimodal contents (i.e., ‘X’ could be the image, video, audio, or others), and the outputs are textual responses from LLM. There are well-established data of this type, e.g., LLaVA [52], miniGPT-4 [109], VideoChat [44], where we directly employ them for our tuning purpose.
‘Text’ — ‘Text+X’ Data Significantly unlike existing MM-LLMs, in our any-to-any scenario, the target not only includes the generations of texts, but also the multimodal contents, i.e., ‘Text+X’. Thus, we construct the ‘Text’ — ‘Text+X’ data, i.e., text-to-multimodal (namely T2M) data. Based on the rich volume of ‘X-caption’ pairs from the existing corpus and benchmarks [71, 50, 5, 38], with some templates, we borrow GPT-4 to produce varied textual instructions to wrap the captions, and result in the data.
MosIT Data Crafting high-quality instructions that comprehensively cover the desired target behaviors is non-trivial. We notice that the above IT datasets fail to meet the requirements for our any-to-any MM-LLM scenario. Firstly, during a human-machine interaction, users and LLM involve diverse and dynamically changing modalities in their inputs and outputs. Additionally, we allow multi-turn conversations in the process, and thus processing and understanding of complex user intentions is required. However, the above two types of data lack variable modalities, and also are relatively short in dialogues, failing to mimic real-world scenarios adequately.
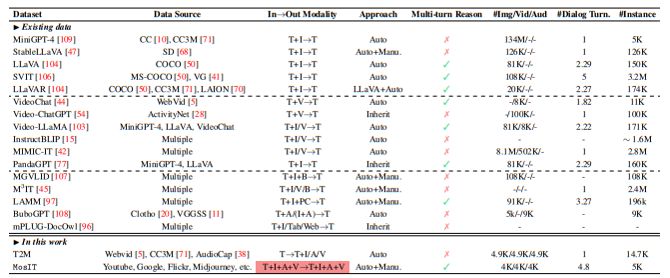
To facilitate the development of any-to-any MM-LLM, we propose a novel Modality-switching Instruction Tuning (MosIT). MosIT not only supports complex cross-modal understanding and reasoning but also enables sophisticated multimodal content generation. In conjunction with MosIT, we manually and meticulously construct a high-quality dataset. The MosIT data encompasses a wide range of multimodal inputs and outputs, offering the necessary complexity and variability to facilitate the training of MM-LLMs that can handle diverse user interactions and deliver desired responses accurately. Specifically, we design some template dialogue examples between a ‘Human’ role and a ‘Machine’ role, based on which we prompt the GPT-4 to generate more conversations under various scenarios with more than 100 topics or keywords. The interactions are required to be diversified, e.g., including both straightforward and implicit requirements by the ‘Human’, and execution of perception, reasoning, suggestion, planning, etc., by the ‘Machine’. And the interactive content should be logically connected and semantically inherent and complex, with in-depth reasoning details in each response by the ‘Machine’. Each conversation should include 3-7 turns (i.e., QA pairs), where the ‘Human’-‘Machine’ interactions should involve multiple modalities at either the input or output side, and switch the modalities alternately. Whenever containing multimodal contents (e.g., image, audio, and video) in the conversations, we look for the best-matched contents from the external resources, including the retrieval systems, e.g., Youtube[7] , and even AIGC tools, e.g., Stable-XL [63], Midjourney[8] . After human inspections and filtering of inappropriate instances, we obtain a total of 5K dialogues in high quality. In Table 2 we compare the existing multimodal IT datasets with our MosIT data
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
[7] https://www.youtube.com/
[8] https://www.midjourney.com/