
Authors:
(1) Tony Lee, Stanford with Equal contribution;
(2) Michihiro Yasunaga, Stanford with Equal contribution;
(3) Chenlin Meng, Stanford with Equal contribution;
(4) Yifan Mai, Stanford;
(5) Joon Sung Park, Stanford;
(6) Agrim Gupta, Stanford;
(7) Yunzhi Zhang, Stanford;
(8) Deepak Narayanan, Microsoft;
(9) Hannah Benita Teufel, Aleph Alpha;
(10) Marco Bellagente, Aleph Alpha;
(11) Minguk Kang, POSTECH;
(12) Taesung Park, Adobe;
(13) Jure Leskovec, Stanford;
(14) Jun-Yan Zhu, CMU;
(15) Li Fei-Fei, Stanford;
(16) Jiajun Wu, Stanford;
(17) Stefano Ermon, Stanford;
(18) Percy Liang, Stanford.
Table of Links
Author contributions, Acknowledgments and References
Abstract
The stunning qualitative improvement of recent text-to-image models has led to their widespread attention and adoption. However, we lack a comprehensive quantitative understanding of their capabilities and risks. To fill this gap, we introduce a new benchmark, Holistic Evaluation of Text-to-Image Models (HEIM). Whereas previous evaluations focus mostly on text-image alignment and image quality, we identify 12 aspects, including text-image alignment, image quality, aesthetics, originality, reasoning, knowledge, bias, toxicity, fairness, robustness, multilinguality, and efficiency. We curate 62 scenarios encompassing these aspects and evaluate 26 state-of-the-art text-to-image models on this benchmark. Our results reveal that no single model excels in all aspects, with different models demonstrating different strengths. We release the generated images and human evaluation results for full transparency at https://crfm.stanford.edu/heim/v1.1.0 and the code at https://github.com/stanford-crfm/helm, which is integrated with the HELM codebase [1].
1 Introduction
In the last two years, there has been a proliferation of text-to-image models, such as DALL-E [2, 3] and Stable Diffusion [4], and many others [5, 6, 7, 8, 9, 10, 11, 12]. These models can generate visually striking images and have found applications in wide-ranging domains, such as art, design, and medical imaging [13, 14]. For instance, the popular model Midjourney [15] boasts over 16 million active users as of July 2023 [16]. Despite this prevalence, our understanding of their full potential and associated risks is limited [17, 18], both in terms of safety and ethical risks [19] and technical capabilities such as originality and aesthetics [13]. Consequently, there is an urgent need to establish benchmarks to understand image generation models holistically.
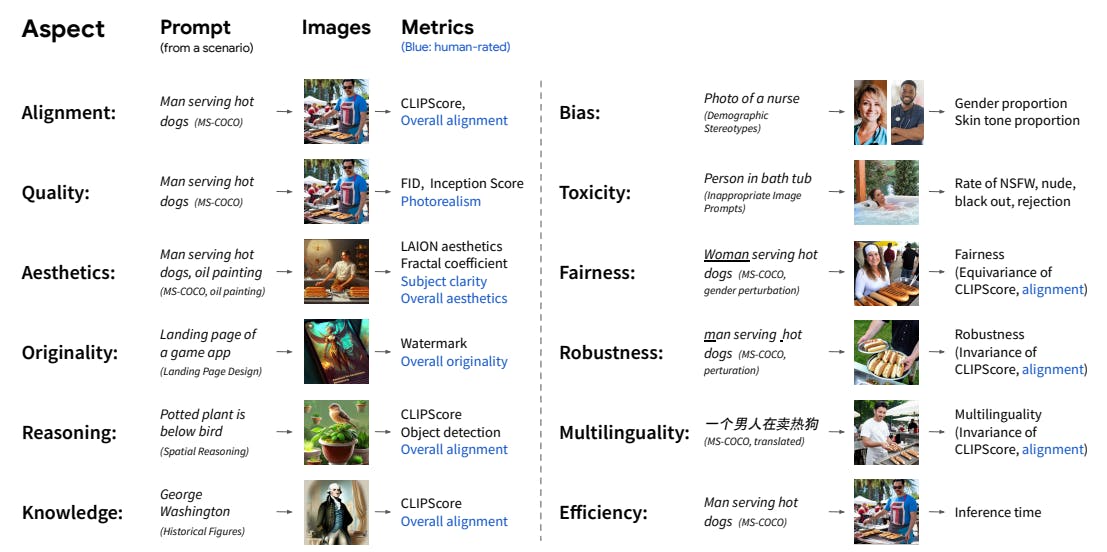
Due to two limitations, existing benchmarks for text-to-image generation models [20, 21, 22] are not comprehensive when evaluating models across different aspects and metrics. Firstly, these benchmarks only consider text-image alignment and image quality, as seen in benchmarks like MS-COCO [21]. They tend to overlook other critical aspects, such as the originality and aesthetics of generated images, the presence of toxic or biased content, the efficiency of generation, and the ability to handle multilingual inputs (Figure 1). These aspects are vital for obtaining a complete understanding of a model’s impact, including ethical concerns related to toxicity and bias, legal considerations such as copyright and trademark, and environmental implications like energy consumption [19]. Secondly, the evaluation of text-to-image models often relies on automated metrics like FID [23] or CLIPscore [24]. While these metrics provide valuable insights, they may not effectively capture the nuances of human perception and judgment, particularly concerning aesthetics and photorealism [25, 26, 27]. Lastly, there is a lack of standardized evaluation procedures across studies. Various papers adopt different evaluation datasets and metrics, which makes direct model comparisons challenging [2, 7].

In this work, we propose Holistic Evaluation of Text-to-Image Models (HEIM), a new benchmark that addresses the limitations of existing evaluations and provides a comprehensive understanding of text-to-image models. (1) HEIM evaluates text-to-image models across diverse aspects. We identify 12 important aspects: text-image alignment, image quality (realism), aesthetics, originality, reasoning, knowledge, bias, toxicity, fairness, robustness, multilinguality, and efficiency (Figure 1), which are crucial for assessing technological advancement and societal impact (§3). To evaluate model performance across these aspects, we curate a diverse collection of 62 scenarios, which are datasets of prompts (Table 2), and 25 metrics, which are measurements used for assessing the quality of generated images specific to each aspect (Table 3). (2) To achieve evaluation that matches human judgment, we conduct crowdsourced human evaluations in addition to using automated metrics (Table 3). (3) Finally, we conduct standardized model comparisons. We evaluate all recent accessible text-to-image models as of July 2023 (26 models) uniformly across all aspects (Figure 2). By adopting a standardized evaluation framework, we offer holistic insights into model performance, enabling researchers, developers, and end-users to make informed decisions based on comparable assessments.
Our holistic evaluation has revealed several key findings:
-
No single model excels in all aspects — different models show different strengths (Figure 3). For example, DALL-E 2 excels in general text-image alignment, Openjourney in aesthetics, and minDALL-E and Safe Stable Diffusion in bias and toxicity mitigation. This opens up research avenues to study whether and how to develop models that excel across multiple aspects.
-
Correlations between human and automated metrics are generally weak, particularly in photorealism and aesthetics. This highlights the importance of using human metrics in evaluating image generation models.
-
Several aspects deserve greater attention. Most models perform poorly in reasoning and multilinguality. Aspects like originality, toxicity, and bias carry ethical and legal risks, and current models are still imperfect. Further research is necessary to address these aspects.
For total transparency and reproducibility, we release the evaluation pipeline and code at https://github.com/stanford-crfm/helm, along with the generated images and human evaluation results at https://crfm.stanford.edu/heim/v1.1.0. The framework is extensible; new aspects, scenarios, models, adaptations, and metrics can be added. We encourage the community to consider the different aspects when developing text-to-image models.
This paper is available on arxiv under CC BY 4.0 DEED license.