

Authors:
(1) Shengqiong Wu, NExT++, School of Computing, National University of Singapore;
(2) Hao Fei ,from NExT++, School of Computing at the National University of Singapore, serves as the corresponding author: [email protected].
(3) Leigang Qu, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: [email protected];;
(4) Wei Ji, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: [email protected];;
(5) Tat-Seng Chua, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: [email protected];.
Table of Links
- Abstract and 1. Introduction
- 2 Related Work
3 Overall Architecture
4 Lightweight Multimodal Alignment Learning - 5 Modality-switching Instruction Tuning
- 5.1 Instruction Tuning
- 5.2 Instruction Dataset
- 6 Experiments
- 6.1 Any-to-any Multimodal Generation and 6.2 Example Demonstrations
- 7 Conclusion and References
3 Overall Architecture
Figure 1 presents the schematic overview of the framework. NExT-GPT consists of three main tiers: the encoding stage, the LLM understanding and reasoning stage, and the decoding stage.
Multimodal Encoding Stage First, we leverage existing well-established models to encode inputs of various modalities. There are a set of alternatives of encoders for different modalities, e.g., QFormer [43], ViT [19], CLIP [65]. Here we take advantage of the ImageBind [25], which is a unified high-performance encoder across six modalities. With ImageBind, we are spared from managing many numbers of heterogeneous modal encoders. Then, via the linear projection layer, different input representations are mapped into language-like representations that are comprehensible to the LLM.
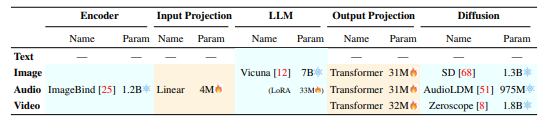
LLM Understanding and Reasoning Stage An LLM is used as the core agent of NExT-GPT. Technically, we employ the Vicuna[2] [12], which is the open-source text-based LLM that is widely used in the existing MM-LLMs [77, 103]. LLM takes as input the representations from different modalities and carries out semantic understanding and reasoning over the inputs. It outputs 1) the textual responses directly, and 2) signal tokens of each modality that serve as instructions to dictate the decoding layers whether to generate multimodal contents, and what content to produce if yes.
Multimodal Generation Stage Receiving the multimodal signals with specific instructions from LLM (if any), the Transformer-based output projection layers map the signal token representations into the ones that are understandable to following multimodal decoders. Technically, we employ the current off-the-shelf latent conditioned diffusion models of different modal generations, i.e., Stable Diffusion (SD)[3]for image synthesis [68], Zeroscope[4] for video synthesis [8], and AudioLDM[5] for audio synthesis [51]. The signal representations are fed into the condition encoders of the conditioned diffusion models for content generation.
In Table 1 we summarize the overall system configurations. It is noteworthy that in the entire system, only the input and output projection layers of lower-scale parameters (compared with the overall huge capacity framework) are required to be updated during the following learning, with all the rest encoders and decoders frozen. That is, 131M(=4+33+31+31+32) / [131M + 12.275B(=1.2+7+1.3+1.8+0.975)], only 1% parameters are to be updated. This is also one of the key advantages of our MM-LLM.

This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.
[2] https://huggingface.co/lmsys/vicuna-7b-delta-v0, 7B, version 0
[3] https://huggingface.co/runwayml/stable-diffusion-v1-5, version 1.5.
[4] https://huggingface.co/cerspense/zeroscope_v2_576w, version zeroscope_v2_576w.
[5] https://audioldm.github.io/, version audioldm-l-full.
[6] Except the text inputs, which will be directly fed into LLM.