

Authors:
(1) Shengqiong Wu, NExT++, School of Computing, National University of Singapore;
(2) Hao Fei ,from NExT++, School of Computing at the National University of Singapore, serves as the corresponding author: [email protected].
(3) Leigang Qu, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: [email protected];;
(4) Wei Ji, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: [email protected];;
(5) Tat-Seng Chua, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: [email protected];.
Table of Links
- Abstract and 1. Introduction
- 2 Related Work
3 Overall Architecture
4 Lightweight Multimodal Alignment Learning - 5 Modality-switching Instruction Tuning
- 5.1 Instruction Tuning
- 5.2 Instruction Dataset
- 6 Experiments
- 6.1 Any-to-any Multimodal Generation and 6.2 Example Demonstrations
- 7 Conclusion and References
Abstract
While recently Multimodal Large Language Models (MM-LLMs) have made exciting strides, they mostly fall prey to the limitation of only input-side multimodal understanding, without the ability to produce content in multiple modalities. As we humans always perceive the world and communicate with people through various modalities, developing any-to-any MM-LLMs capable of accepting and delivering content in any modality becomes essential to human-level AI. To fill the gap, we present an end-to-end general-purpose any-to-any MM-LLM system, NExT-GPT. We connect an LLM with multimodal adaptors and different diffusion decoders, enabling NExT-GPT to perceive inputs and generate outputs in arbitrary combinations of text, images, videos, and audio. By leveraging the existing well-trained highly-performing encoders and decoders, NExT-GPT is tuned with only a small amount of parameter (1%) of certain projection layers, which not only benefits low-cost training and also facilitates convenient expansion to more potential modalities. Moreover, we introduce a modality-switching instruction tuning (MosIT) and manually curate a high-quality dataset for MosIT, based on which NExT-GPT is empowered with complex cross-modal semantic understanding and content generation. Overall, our research showcases the promising possibility of building a unified AI agent capable of modeling universal modalities, paving the way for more human-like AI research in the community.
1 Introduction
Recently, the topic of Artificial Intelligence Generated Content (AIGC) has witnessed unprecedented advancements with certain technologies, such as ChatGPT for text generation [59] and diffusion models for visual generation [21]. Among these, the rise of Large Language Models (LLMs) has been particularly remarkable, e.g., Flan-T5 [13], Vicuna [12], LLaMA [80] and Alpaca [79], showcasing their formidable human-level language reasoning and decision-making capabilities, shining a light on the path of Artificial General Intelligence (AGI). Our world is inherently multimodal, and humans perceive the world with different sensory organs for varied modal information, such as language, images, videos, and sounds, which often complement and synergize with each other. With such intuition, the purely text-based LLMs have recently been endowed with other modal understanding and perception capabilities of visual, video, audio, etc.
A notable approach involves employing adapters that align pre-trained encoders in other modalities to textual LLMs. This endeavor has led to the rapid development of multimodal LLMs (MM-LLMs), such as BLIP-2 [43], Flamingo [1], MiniGPT-4 [109], Video-LLaMA [103], LLaVA [52], PandaGPT [77], SpeechGPT [102]. Nevertheless, most of these efforts pay the attention to the multimodal content understanding at the input side, lacking the ability to output content in multiple modalities more than texts. We emphasize that real human cognition and communication indispensably require seamless transitions between any modalities of information. This makes the exploration of any-to-any MM-LLMs critical to achieving real AGI, i.e., accepting inputs in any modality and delivering responses in the appropriate form of any modality.
Certain efforts have been made to mimic the human-like any-to-any modality conversion. Lately, CoDi [78] has made strides in implementing the capability of simultaneously processing and generating arbitrary combinations of modalities, while it lacks the reasoning and decision-making prowess of LLMs as its core, and also is limited to the simple paired content generation. On the other hand, some efforts, e.g., Visual-ChatGPT [88] and HuggingGPT [72] have sought to combine LLMs with external tools to achieve approximately the ‘any-to-any’ multimodal understanding and generation. Unfortunately, these systems suffer from critical challenges due to the complete pipeline architecture. First, the information transfer between different modules is entirely based on discrete texts produced by the LLM, where the cascade process inevitably introduces noise and propagates errors. More critically, the entire system only leverages existing pre-trained tools for inference only. Due to the lack of overall end-to-end training in error propagation, the capabilities of content understanding and multimodal generation can be very limited, especially in interpreting intricate and implicit user instructions. In a nutshell, there is a compelling need for constructing an end-to-end MM-LLM of arbitrary modalities.
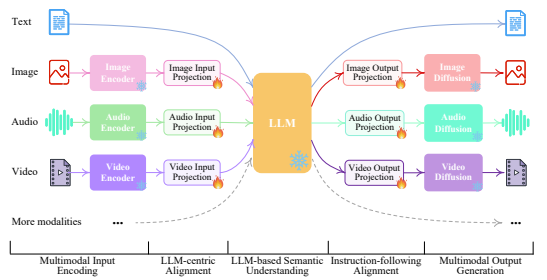
In pursuit of this goal, we present NExT-GPT, an any-to-any MM-LLM designed to seamlessly handle input and output in any combination of four modalities: text, images, videos, and audio. As depicted in Figure 1, NExT-GPT comprises three tiers. First, we leverage established encoders to encode inputs in various modalities, where these representations are projected into language-like representations comprehensible to the LLM through a projection layer. Second, we harness an existing open-sourced LLM as the core to process input information for semantic understanding and reasoning. The LLM not only directly generates text tokens but also produces unique “modality signal” tokens that serve as instructions to dictate the decoding layers whether & what modal content to output correspondingly. Third, the produced multimodal signals with specific instructions, after projection, route to different encoders and finally generate content in corresponding modalities.
As NExT-GPT encompasses encoding and generation of various modalities, training the system from scratch would entail substantial costs. Instead, we take advantage of the existing pre-trained high-performance encoders and decoders, such as Q-Former [43], ImageBind [25] and the stateof-the-art latent diffusion models [68, 69, 8, 2, 51, 33]. By loading the off-the-shelf parameters, we not only avoid cold-start training but also facilitate the potential growth of more modalities. For the feature alignment across the three tiers, we consider fine-tuning locally only the input projection and output projection layers, with an encoding-side LLM-centric alignment and decodingside instruction-following alignment, where the minimal computational overhead ensures higher efficiency. Furthermore, to empower our any-to-any MM-LLM with human-level capabilities in complex cross-modal generation and reasoning, we introduce a modality-switching instruction tuning (termed Mosit), equipping the system with sophisticated cross-modal semantic understanding and content generation. To combat the absence of such cross-modal instruction tuning data in the community, we manually collect and annotate a Mosit dataset consisting of 5,000 samples of high quality. Employing the LoRA technique [32], we fine-tune the overall NExT-GPT system on MosIT data, updating the projection layers and certain LLM parameters.
Overall, this work showcases the promising possibility of developing a more human-like MM-LLM agent capable of modeling universal modalities. The contributions of this project are as follows:
• We for the first time present an end-to-end general-purpose any-to-any MM-LLM, NExTGPT, capable of semantic understanding and reasoning and generation of free input and output combinations of text, images, videos, and audio.
• We introduce lightweight alignment learning techniques, the LLM-centric alignment at the encoding side, and the instruction-following alignment at the decoding side, efficiently requiring minimal parameter adjustments (only 1% params) for effective semantic alignment.
• We annotate a high-quality modality-switching instruction tuning dataset covering intricate instructions across various modal combinations of text, images, videos, and audio, aiding MM-LLM with human-like cross-modal content understanding and instruction reasoning.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.