

Authors:
(1) Thuat Nguyen, Dept. of Computer Science, University of Oregon, OR, USA;
(2) Chien Van Nguyen, Dept. of Computer Science, University of Oregon, OR, USA;
(3) Viet Dac Lai, Dept. of Computer Science, University of Oregon, OR, USA;
(4) Hieu Man, Dept. of Computer Science, University of Oregon, OR, USA;
(5) Nghia Trung Ngo, Dept. of Computer Science, University of Oregon, OR, USA;
(6) Franck Dernoncourt, Adobe Research, USA;
(7) Ryan A. Rossi, Adobe Research, USA;
(8) Thien Huu Nguyen, Dept. of Computer Science, University of Oregon, OR, USA.
Table of Links
4 Related Work
Compared to other NLP tasks, language models can be trained with unlabeled data, enabling efficient data collection to produce gigantic scales for
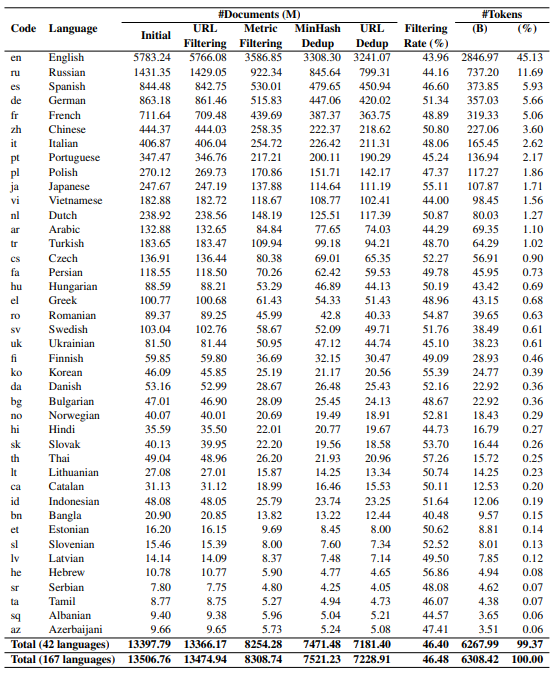
the training data. There are two primary types of data commonly used for training LLMs: curated data and web crawl data. Curated data typically consists of well-written and well-formatted text from targeted sources and domains, e.g., Wikipedia articles, books, newswire articles, and scientific papers, as used for the “The Pile” (Gao et al., 2020) and “BookCorpus” (Zhu et al., 2015) datasets. In contrast, web crawl data encompasses text gathered from a wide array of sources across the internet, varying significantly in terms of format and writing styles, e.g., blogs, social media posts, news articles, and advertisements. CommonCrawl (CC) is a widely-used web crawl repository that has collected petabytes of data over the Internet for 12 years. To this end, curated data is frequently considered to possess higher quality, which has resulted in its preference for training early LLMs, e.g., BERT (Devlin et al., 2019) and GPT-2 (Radford et al., 2019). However, as the demand for larger models has grown, web crawl data has gained more attention as it contributes a substantial portion to the training data of recent LLMs, e.g., RoBERTa (Liu et al., 2019), BART (Lewis et al., 2020), T5 (Raffel et al., 2020), GPT-3 (Rae et al., 2021), LLaMa (Touvron et al., 2023), MPT (MosaicML, 2023), and Falcon (Almazrouei et al., 2023). As such, different extractions of CC has been produced to train such LLMs, including C4 (Raffel et al., 2020), CC-News (Nagel), and STORIES (Trinh and Le, 2018)
Regarding the accessibility of training data, datasets used to train early LLMs are often made available to the public (Devlin et al., 2019; Raffel et al., 2020). However, in the case of the most recent state-of-the-art (SOTA) generative LLMs, their training datasets are not released fully, potentially due to commercial interests. This applies not only to proprietary models like ChatGPT and GPT-4 but also to models that claim to be opensource models such as LLaMa, MPT, Falcon, and BLOOM (Scao et al., 2022). To address the transparency issue with existing LLMs, recent efforts have been made to replicate and release the training datasets for the state-of-the-art LLMs, i.e., RedPajama (Computer, 2023), SlimPajama, and AI2 Dolma. The key distinctions for these datasets concern their large-scale text data that has been meticulously cleaned and document-level deduplicated to ensure high quality for training LLMs. Nonetheless, a common drawback of these opensource datasets is that they remain predominantly focused on English data, offering limited data for other languages.
To obtain a multilingual large-scale dataset for training LLMs, it is more convenient to exploit web-scrape datasets such as CC to enable efficient data collection with up-to-date information in multiple languages. In addition, to ensure high quality for high-performing LLMs, it is necessary to extensively clean and deduplicate the multilingual data to avoid noisy and irrelevant content, e.g., low-quality machine-generated text and adult content (Trinh and Le, 2018; Kreutzer et al., 2022; Raffel et al., 2020). As such, a typical data processing pipeline to generate high-quality datasets can involve multiple steps, as demonstrated by FastText (Joulin et al., 2016), CC-Net (Wenzek et al., 2020), the BigScience ROOTS corpus for the BLOOM models (Laurençon et al., 2022; Scao et al., 2022), the RefinedWeb dataset for the Falcon model (Penedo et al., 2023; Almazrouei et al., 2023), and the dataset to train the LLaMa models (Touvron et al., 2023). The first step necessitates in such pipelines language identification to appropriately assign data to their corresponding languages (Joulin et al., 2016). The next steps features various dataset-specific rules and heuristics to filter undesirable content according to the ratios of special characters, short lines, bad words, among others (Grave et al., 2018; Laurençon et al., 2022). The data can also be filtered via lightweight models, e.g., via the KenLM language models (Heafield, 2011), to avoid noisy documents (Wenzek et al., 2020). Finally, data deduplication should be performed to remove similar or repeated information (Laurençon et al., 2022; Penedo et al., 2023). An important step in this regard involves fuzzy deduplication at document level, e.g., via MinHash (Broder, 1997), to eliminate similar documents, thus mitigating memorization and improving the generalization for resulting LLMs (Lee et al., 2022).
To this end, while there are multilingual opensource datasets with text data in multiple languages, such as mC4 (Xue et al., 2021), OSCAR (Ortiz Suárez et al., 2019), CC100 (Wenzek et al., 2020; Conneau et al., 2020), and the BigScience ROOT corpus (Laurençon et al., 2022), their quality and scale do not meet the requirements for effectively training LLMs, particularly generative models such as GPT. For example, as highlighted in the introduction, both mC4 and OSCAR lack fuzzy dedu- plication for the data at the document level. mC4 also suffers from its poorer language identification due to the use of cld3. BigScience ROOTS only provides a small sample data for 46 languages while CC100 does not have information beyond 2018. Our dataset CulturaX thus comprehensively addresses the issues for the existing datasets, offering a multilingual, open-source, and large-scale dataset with readily usable and high-quality data to train LLMs.
This paper is available on arxiv under CC BY 4.0 DEED license.