

Authors:
(1) Thuat Nguyen, Dept. of Computer Science, University of Oregon, OR, USA;
(2) Chien Van Nguyen, Dept. of Computer Science, University of Oregon, OR, USA;
(3) Viet Dac Lai, Dept. of Computer Science, University of Oregon, OR, USA;
(4) Hieu Man, Dept. of Computer Science, University of Oregon, OR, USA;
(5) Nghia Trung Ngo, Dept. of Computer Science, University of Oregon, OR, USA;
(6) Franck Dernoncourt, Adobe Research, USA;
(7) Ryan A. Rossi, Adobe Research, USA;
(8) Thien Huu Nguyen, Dept. of Computer Science, University of Oregon, OR, USA.
Table of Links
2 Multilingual Dataset Creation
To develop a multilingual public dataset for LLMs, our strategy is to combine mC4 (Xue et al., 2021) and OSCAR (Ortiz Suárez et al., 2019; Abadji et al., 2021, 2022), two largest multilingual datasets at our disposal. We then process the data with an extensive pipeline, involving two major steps of cleaning and deduplication, to produce an enormous and high-quality dataset for multilingual LLMs.
mC4 is a multilingual document-level dataset, originally created to train the multilingual encoderdecoder model mT5 (Xue et al., 2021) for 101 languages. This dataset is extracted from 71 monthly snapshots from CC by removing pages with less than three long lines (line length filter), pages with bad words, and duplicated lines across documents. Language identification for the pages in mC4 is done by the cld3 tool (Botha et al., 2017) [5], which is a small feed-forward network (Xue et al., 2021). Any pages with a language confidence below 0.95% are excluded. mC4 is deduplicated with exact match at the document level; however, fuzzy document-level deduplication is not performed. We utilize the latest version of mC4 (version 3.1.0)[6] prepared by AllenAI in this work.
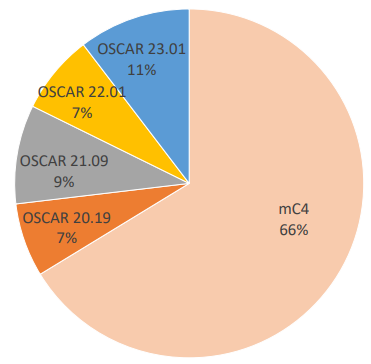
A notable aspect of our dataset pertains to the web-based origin of our selected datasets, mC4 and OSCAR, extracted from CC. This differs from certain previous work (Radford et al., 2019; MosaicML, 2023; Touvron et al., 2023) that has also relied on curated datasets like The Pile (Gao et al., 2020) and BookCorpus (Zhu et al., 2015) to train LLMs, presuming their higher overall quality. However, in the context of multilingual settings, we argue that web-scraped datasets can be a more suitable approach, as curated datasets of superior quality might not be available for various languages. Our strategy of using web-scraped data facilitates efficient data collection across multiple languages, contributing to enhanced training data scales. Furthermore, recent studies have demonstrated the effectiveness of cleaning web-scraped data to yield state-of-the-art LLMs (Raffel et al., 2020; Almazrouei et al., 2023). In total, the combination of mC4 and OSCAR provides us 13.5B documents for further processing. Figure 1 illustrates the distribution of the document counts for mC4 and the four available versions of OSCAR in our initial dataset.
2.1 Data Cleaning
Given the combination of the mC4 and OSCAR datasets, we first perform a comprehensive data cleaning procedure to remove noisy and bad content from the data, including language identification, ULR-based filtering, metric-based cleaning, and document refinement.
Language Identification: A particular issue concerns the use of two different language identification tools, i.e., cld3 and FastText, for mC4 and OSCAR (respectively). It has been shown in previous studies that cld3 is significantly worse than FastText, causing substantially more language detection errors for mC4 (Kreutzer et al., 2022). In fact, compared to several other language detectors, FastText has demonstrated state-of-the-art performance over benchmark datasets[7]. To this end, our first data cleaning step involves applying FastText to re-predict the languages for the documents in mC4. Documents whose predicted languages are different from the provided ones in mC4 will be removed from the dataset. The rationale is to avoid documents that are confusing for the language detectors cld3 and FastText, thus potentially introducing noise for the data. Finally, to ensure the highest quality, we remove data for any language found in mC4 but not supported by FastText.
URL-based Filtering: In the next step, we aim to eliminate pages from the known toxic and harmful sources to reduce relevant risks from our data. In particular, we leverage the latest UT1 blacklist of URLs and domains provided by the University of Toulouse to support Internet use regulation for administrators at schools. This list involves sites from different topics, including pornography, grumbling, and hacking, that should be discarded for LLM training. Updated twice to thrice per week, the blacklist involves more than 3.7M records that are contributed by both human and robots (e.g., search engines, known addresses and indexes) (Abadji et al., 2022). As such, we remove any page from our dataset whose associated URL matches a site in the blacklist. This step is helpful for our dataset as the blacklist is not employed before for the mC4 dataset. In addition, although OSCAR has already used this blacklist for data cleaning, our approach incorporates the most up-to-date information from the list, which might not be available for the current distributions of OSCAR.
Metric-based Cleaning: To enhance the dataset’s quality, motivated by the data processing pipeline from the BigScience’s ROOTS corpus for BLOOM (Laurençon et al., 2022; Scao et al., 2022), we further utilize the distributions for various dataset metrics to identify and filter outlying documents. Each metric provides a singular value for every document within the dataset, quantifying specific attributes such as number_words, stopword_ratios, and perplexity_score for each document. For each metric and its range of possible values within the dataset, a threshold will be determined to partition the range into two zones: a normal range and an abnormal range. The abnormal range is designated for documents exhibiting metric values significantly deviating from the norm, classifying them as outliers/noises, and consequently, these outliers are removed from our dataset. As such, we employ a comprehensive array of dataset metrics, which will be collectively employed to refine our dataset, as outlined below:
• Number of words
• Character repetition ratio
• Word repetition ratio
• Special character ratio
• Stop word ratio
• Flagged word ratio
• Language identification confidence
• Perplexity score
• Document length (number of characters)
• Number of lines
• Short line length ratio • Short line ratio
The last four metrics are suggested by the OSCAR dataset while the others are inherited from the BigScience ROOTS corpus’s pipeline to process OSCAR data. For the perplexity score, following the BigScience ROOTS corpus, we train a SentencePiece tokenizer (Kudo, 2018) and 5-gram KneserNey language models as provided in the KenLM library (Heafield, 2011) using the 20230501 dumps of Wikipedia. Documents displaying high perplexity scores based on these KenLM models are considered notably different from Wikipedia articles. This indicates a level of noise that will be excluded from our dataset (Wenzek et al., 2020). The tokenizer will also be used to obtain the number of words/tokens in the documents for our metrics. We publicly release our KenLM models in HuggingFace[8] to faciliate future exploration.
Repeated information (e.g., words, paragraphs) can appear in the web-curated data due to crawling errors and low-quality sources, causing detrimental consequences for training LLMs (Holtzman et al., 2019). The character and word repetition ratios are thus designed to avoid documents with excessively repeated information. High frequencies of special characters, stop words, or flagged words can indicate noisy and low-quality documents. We thus utilize the stop word and flagged word lists for different languages to compute their ratios for document removal. In addition to the stop word and flagged word lists provided by BigScience ROOTS for their 13 languages, we further collect dictionaries for these types of words for other languages. We prioritize the lists that have been shared on personal GitHub accounts for various languages, as these are often crafted by native speakers and exhibit higher quality. Moreover, lower language identification confidence might also suggest noisy language structures for the data. For each document in the dataset, we thus obtain a language identification confidence via the probability that FastText assigns to its corresponding language to aid data filtering. Finally, for the short line-based criteria, we implement a threshold of 100 characters to classify lines as short, as used by OSCAR. Documents with excessive occurrence of short lines will not be retained in our dataset.
Threshold Selection: Given the set of dataset metrics, an important question concerns the selection of appropriate thresholds for each metric and language to generate high-quality multilingual data. In the BigScience ROOTS project (Laurençon et al., 2022), this selection process is carried out by native speakers of 13 languages. The resulting thresholds are employed for the rest of their 46 languages. The project offers a visualization interface that indexes a sample of a few thousand documents per language, enabling users to monitor data statistics as they adjust thresholds for the metrics. However, this process cannot be easily extended to different languages due to the requirement of experienced native speakers, which incurs significant costs. Furthermore, the limited sample sizes hinder the representativeness of the chosen thresholds for the full datasets. In our analysis, we observe that some selected thresholds for certain languages within BigScience ROOTS almost fall outside the value ranges for the entire dataset, leading to the deactivation of the corresponding metrics.
To address these issues, we leverage a variant of the Interquartile Range (IQR) method (Dekking et al., 2007) to select appropriate thresholds for the filtering metrics for our dataset. For each metric and language, we generate a distribution of its possible values across the entire dataset for the language. There is an exception for languages with substantial amounts of data, such as Spanish and Russian, where only 25% of the data is used to calculate these distributions. Afterward, we compute the Q1-th and Q3-th percentiles of the distribution (Q1 < Q3) and use them for the thresholds for our filtering metrics. In particular, the lower Q1- th percentile will be chosen for the metrics that favor high values (e.g., language identification confidence), while metrics favoring low values (e.g., perplexity scores and document length) will utilize the upper Q3-th percentile. We investigate different values for (Q1, Q3), considering (25, 75), (20, 80), (15, 85), (10, 90), and (5, 95). The selection of Q1 = 10 and Q2 = 90 has achieved the best data quality for a sample of languages in our examination.
It is worth emphasizing that the utilization of percentiles for threshold selection enables our approach to efficiently draw upon more extensive data samples for each language compared to those employed in the BigScience ROOTS project. This results in more reliable thresholds for the full datasets over different languages. Specifically, concerning the large languages where only a 25% data sample is employed to compute the value distribution for a metric, we observe that the proportion of discarded data to the entire dataset closely aligns with that of the data sample when applying the same selected filtering threshold. This underscores the representativeness of the thresholds selected through our methodology. Finally, once the thresholds for the metrics in a given language have been determined, we will eliminate any document that surpasses a metric’s threshold and enters the unfavorable range of the data.
Document Refinement: The previous cleaning steps are done at the dataset level, aiming to remove low-quality documents from the dataset. In this step, we further clean the retained documents to improve the quality. It is important to note that our prior metric-based filtering step plays a vital role in eliminating highly noisy documents, which, in turn, streamlines the process of developing effective document cleaning rules during this step. Notably, since the documents from mC4 and OSCAR are extracted from HTML pages crawled from the Internet, a significant portion of them may carry crawling and extraction errors, including long JavaScript lines and extraneous content. Consequently, filtering out these documents greatly simplifies our task of designing rules to clean the documents within our dataset.
As such, for each document, we eliminate its noisy or irrelevant portions via a series of operations. First, we remove any short lines located at the end of each document, as these lines typically contain footer details or unhelpful information from the websites. Second, we eliminate the lines that contain words from our list of JavaScript (JS) keywords (e.g., “var”. By requiring at least two different types of JS keywords, we reduce the risk of inadvertently omitting helpful content and disrupting the document’s structure.
2.2 Data Deduplication
Despite thorough data cleaning, the remaining dataset might still contain a substantial amount of repeated data due to various reasons, including information being reposted on the web, multiple references to the same articles, boilerplate content, and plagiarism. The duplicated data can thus cause memorization and significantly hinder generalization for LLMs (Lee et al., 2022; Hernandez et al., 2022). Although expensive, data deduplication is thus considered as a crucial step to guarantee the highest quality of data for training LLMs. To this end, we undertake a comprehensive deduplication procedure for our dataset, utilizing MinHash (Broder, 1997) and URLs. This deduplication process is carried out independently for each language. Furthermore, we restrict deduplication to languages that retain over 100K documents following our data cleaning procedures (i.e., 51.5% of our languages), aiming to promote smaller languages within our dataset.
MinHash Deduplication: For each language’s dataset, we first apply the MinHashLSH method (Leskovec et al., 2020) to filter similar documents in the dataset. MinHashLSH is a near deduplication technique based on MinHash (Broder, 1997) with multiple hash functions for n-grams and the Jaccard similarity. Locality-Sensitive Hashing (LSH) is incorporated to improve efficiency by focusing on document pairs that are most likely similar. We leverage a variant of the Spark implementation of MinHashLSH in the text-dedup repo[9], employing 5-grams and a threshold of 0.8 to determine similar documents for the Jaccard similarity. Running MinHashLSH for each language’s dataset, especially for languages with the largest data volumes like English, Russian, Spanish, and Chinese, represents the most computationally expensive operation in our dataset creation effort.
URL-based Deduplication: Finally, we eliminate all documents that share identical URLs with other documents in the dataset. This step is necessary to address situations where various versions of the same articles are linked to identical URLs but have been updated or modified during the publication process, effectively bypassing the near deduplication step. Some URLs for the articles in CC might only display their general domains due to crawling errors. To enhance accuracy, we refrain from removing URLs that only include their general domains.
We utilize 600 AWS c5.24xlarge EC2 instances to preprocess and deduplicate our multilingual dataset. Each instance is equipped with 96 CPU cores, 192GB of memory, and 1TB of disk space. The disk space can be used to replace memory when necessary (e.g., for data deduplication).
This paper is available on arxiv under CC BY 4.0 DEED license.
[5] https://github.com/google/cld3
[6] https://huggingface.co/datasets/mc4
[7] https://modelpredict.com/ language-identification-survey
[8] https://huggingface.co/uonlp/kenlm
[9] https://github.com/ChenghaoMou/text-dedup/ tree/main