

Authors:
(1) Hoon Kim, Beeble AI, and contributed equally to this work;
(2) Minje Jang, Beeble AI, and contributed equally to this work;
(3) Wonjun Yoon, Beeble AI, and contributed equally to this work;
(4) Jisoo Lee, Beeble AI, and contributed equally to this work;
(5) Donghyun Na, Beeble AI, and contributed equally to this work;
(6) Sanghyun Woo, New York University, and contributed equally to this work.
Editor's Note: This is Part 6 of 14 of a study introducing a method for improving how light and shadows can be applied to human portraits in digital images. Read the rest below.
Table of Links
- Abstract and 1. Introduction
- 2. Related Work
- 3. SwitchLight and 3.1. Preliminaries
- 3.2. Problem Formulation
- 3.3. Architecture
- 3.4. Objectives
- 4. Multi-Masked Autoencoder Pre-training
- 5. Data
- 6. Experiments
- 7. Conclusion
Appendix
- A. Implementation Details
- B. User Study Interface
- C. Video Demonstration
- D. Additional Qualitative Results & References
3.4. Objectives
We supervise both intrinsic image attributes and relit images using their corresponding ground truths, obtained from the lightstage. We employ a combination of reconstruction, perceptual [24], adversarial [22], and specular [34] losses.


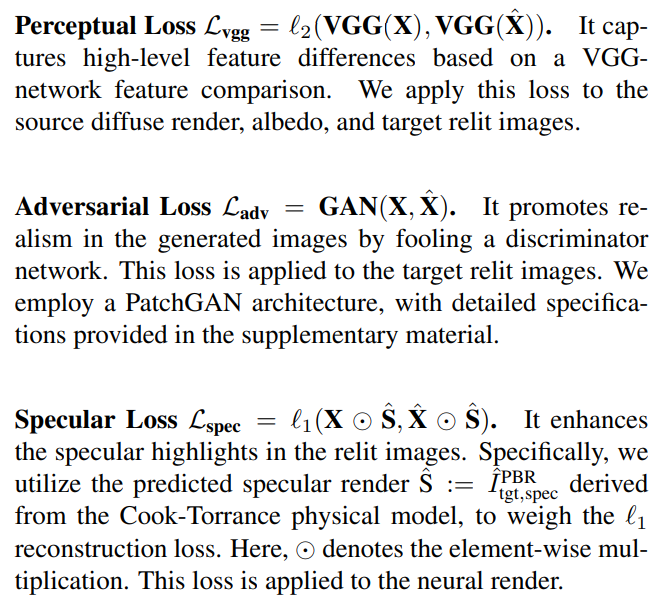
Final Loss. The SwitchLight is trained in an end-to-end manner using the weighted sum of the above losses:
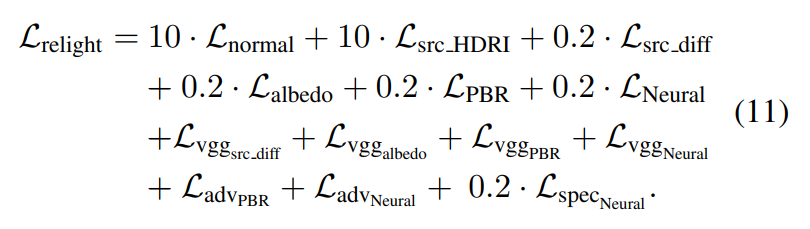
We empirically determined the weighting coefficients.

This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.